

1.hashmap
1.数据结构
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
0.如何遍历hashmap
1.遍历map.keyset(),然后获取value。
2.遍历map.entryset(),然后获取entry。
上面两种方式都不能直接删除或者新增元素。
使用迭代器可以在遍历期间新增和删除元素。
1、map.put(k,v)实现原理
第一步 首先将k,v封装到Node对象当中(节点)。第二步它的底层会调用K的hashCode()方法得出hash值。第三步通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。
如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
计算下标的代码
1 | if ((p = tab[i = (n - 1) & hash]) == null) |
容量与上hash值
2、map.get(k)实现原理
第一步:先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。第二步:通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
3、为何随机增删、查询效率都很高的原因是?
原因:增删是在链表上完成的,而查询只需扫描部分,则效率高。
HashMap集合的key,会先后调用两个方法,hashCode and equals方法,这这两个方法都需要重写。
4.转红黑树
当链表节点大于等于8,tab大于等于64会转成红黑树
5.扩容机制
扩容时需要计算新tab的容量和临界点,并且通过遍历tab的方式将每个entry放到新的tab中,在这个过程中,红黑树可能转换为链表。
1.计算容量和临界点
主要逻辑在下面:
1 | int oldCap = (oldTab == null) ? 0 : oldTab.length; |
2.将老entry移动到新tab
我们思考一个问题,oldtab中有10个entry,我们怎么分配这10个entry在新tab中的下标呢?分配过程中我们还得保证这些entry放入的下标也是满足put运算的。
put计算下标的方法:
假设cap = 1000=16,newcap = 32
那么tab[i=(cap-1)&hash],也就是
11111&111 = 15
10111&111 = 15
所以,以上两个都在同一个下标tab[15]。
而在resize中,计算方法为newIndex = hash&oldcap,也就是hash&1000。
11111&1000=1
10111&1000=0
我们知道同一个index中的entry的hashcode,假设cap转为2进制为n位,那么在n-1位上的特征值都是一样的,但是第n位不一样,刚好resize中就利用了这个区别的特征值,用来区分是在原index还是在原index+oldcap。
所以11111在15+oldcap=31的下标
10111在15的原index
那么思考一下,这个下标计算方式,满足新的tab的put计算方式吗,是的。
我们知道通过put是&tab.length-1的计算方法,并且cap一定是2的n次幂,所以不管怎么扩容,无非就是&时多加几位1罢了。
11111&1111= 31
10111&1111= 15
这样就把原链表分成了两个链表放在了不同的index上。
下面是源码:
1 | table = newTab; |
3.线程安全问题:
多线程put时,存在键值对丢失问题。
例如:
A线程put,进行resize操作。此时正好把老数组某个下标值为空,oldTab[j] = null;
B线程去resize,发现oldTab[j] = null;就没有迁移原来oldTab[j]的元素。
最后A线程把newTab换成oldtab,B线程把newTab1换成newTab,从而导致丢失了 oldTab[j]的元素。
除此之外,正常put也可能让一个key被另一个线程覆盖。
1.7版本的线程安全问题存在死循环,e.next和e相互引用。
2.ArrayList
ArrayList为object数组。默认容量为10.
1 | private static final int DEFAULT_CAPACITY = 10; |
ArrayList的构造方法
1.带容量的构造:
容量>0就创建一个object[cap]数组。
==0就用原来的空数组引用。
<0异常。
2.空构造方法:
用默认空数组复制给elementData.
3.使用集合类初始化:
将集合转为数组后给elementData。
如果不是Object类,强制转为Object类。
如果集合长度为0,使用原来的空数组。
ArrayList的add操作:
1 | public boolean add(E e) { |
1.无下标add
先检查是否能放下,然后数组++放入元素。
2.带下标add
检查index合理性,查看是否需要扩容,将后面的元素复制到后面一个位置。
3.ensureCapacityInternal
扩容如果没有默认容量大,则使用默认容量。
需要的容量大于目前的数组大小时,扩容。
新容量为老容量的1.5倍,如果还是小于需要的容量,那么直接用新容量,新容量大于int最大值用int最大值。
把老数组元素复制到新数组去。
3.ConcurrentHashMap
数据结构:1.7
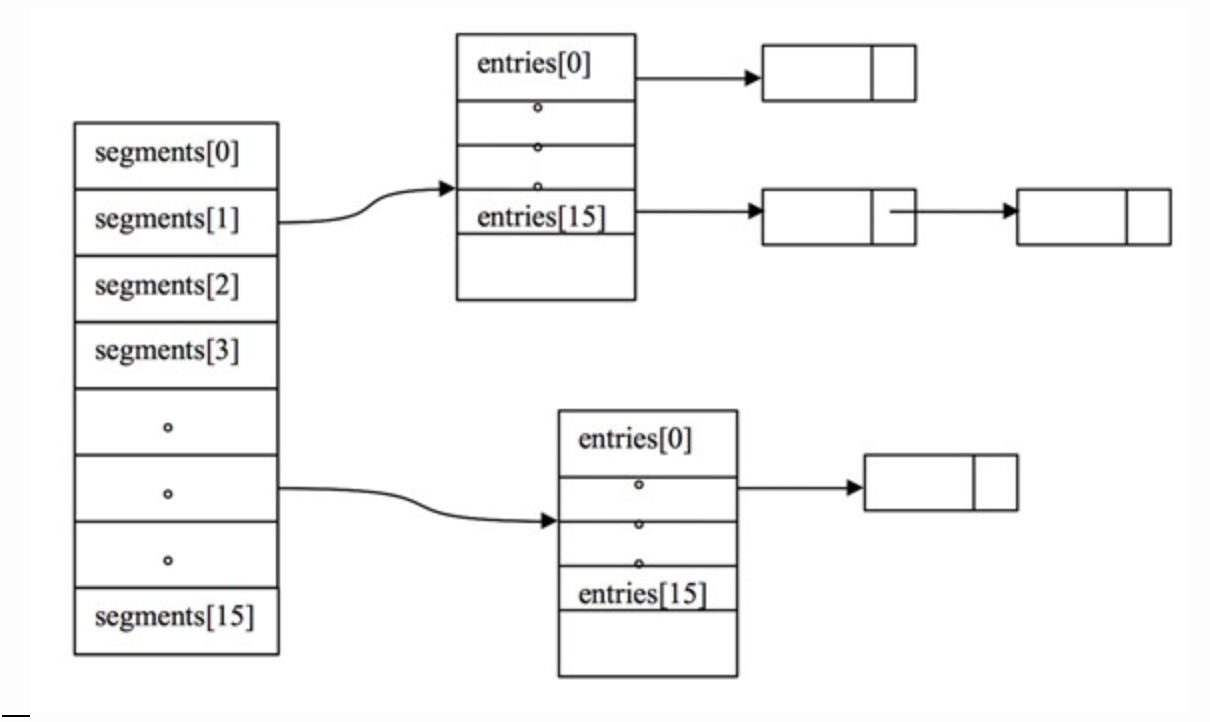
segments数组继承了reentrlock,带有lock功能。
segments下有entry数组,冲突元素通过链表链接。
在Put时先调用segments的lock方法,采用的一种分段锁的思想减少冲突。
1.8 数据结构
Node数组,每个Node都是MapEntry<K,V>。
冲突用链表或者红黑树。
在put时,如果tab[i]为空则使用cas的方式放置第一个node,如果存在使用sync关键字同步tab[i]也就是node对象去同步其他线程操作。
扩容解析:
1 | private transient volatile int sizeCtl; |
sizeCtl=0,代表正常情况,如果为正整数则是当前map有效元素个数。
sizeCtl=-1,代表map正在进行初始化。
sizeCtl<-1,代表map正在进行扩容,代表正在扩容的线程数。
判断过程:
1.while判断>=0是否有扩容条件,sizeCtl<=-1时,代表已经有线程进行扩容或者初始化了。
2.如果tab=null,cas设置-1,去初始化。
3.如果当前数组大小已经大于等于目标容量,代表已经扩容完成,退出循环。
4.如果tab=table也就是没有扩容完成时,在下面几种情况,当前线程不会参与扩容。
1 | if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || |
- Stamp戳记不匹配
- sc == rs + 1 代表线程已经参与了扩容
- sc == rs + MAX_RESIZERS代表参与扩容的线程数已经最大了
- (nt = nextTable) == null 未创建新表,扩容未开始
- transferIndex <= 0同理扩容未开始
- 本文作者: 宏
- 本文链接: http://sasuke.top/2024/08/02/java集合/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!